¿Cómo escalar un servicio?
Francisco


Tener muchos usuarios (data) o que utilicen mucho tus servicios es posiblemente una meta relevante para cualquier empresa, ya que puede demostrar que tu producto soluciona un dolor de las personas. Pero, frente a una gran responsabilidad, viene un gran dolor: ¿cómo soportarlo sin morir?
Durante estos meses he tenido la oportunidad de estudiar un poco sobre estos temas, principalmente aprendiendo tecnologías como Kubernetes, y quería escribir sobre este punto. En mi vida profesional, he estado a cargo de liderar equipos, desarrollar APIs para productos de GenAI y modelos de ML, pero nunca me había tocado revisar temas más de software.
En este artículo escribiré un poco sobre esta tecnología y sobre lo que hay detrás de ella.
Caso hipotético: “Where I am”
Imaginemos que tenemos una app (o webapp) que funciona como un Indoor Navigation para un centro comercial, y que sirve para que los consumidores sepan dónde están las tiendas y baños del centro, usando tracking en tiempo real de la posición de la persona.
Tenemos nuestro backend, que es un conjunto de APIs (Application Programming Interface) para nuestra aplicación. Si tenemos 100 clientes al día que usan nuestros servicios, posiblemente no es un problema, ya que si hostemos nuestro producto en una máquina virtual estándar soportará el tráfico con un buen nivel de servicio.
Pero a medida que pasa el tiempo, más clientes empiezan a usar la aplicación, nuestro producto se hace más popular y las buenas noticias empiezan a aparecer: tenemos más requests diarios. Semana tras semana recibimos miles y miles de solicitudes adicionales, y nuestra máquina ya no soporta tantas peticiones; la latencia es altísima y el servicio se cae por no poder manejar la carga.
¿Qué tenemos que hacer? Escalar. ¿Pero cómo?
Podemos contratar una máquina más potente (más RAM, CPU, etc.) en un sistema cloud. También podríamos comprar un súper computador y hostearlo en tu casa (difícil y costoso). O, en cambio, podemos escalar la solución de manera horizontal.
¿Cómo escalar?
Volvamos a nuestro ejemplo de aplicación. Construimos un producto que el mercado está solicitando; su demanda crece y crece, y necesitamos saber cómo escalarlo, es decir, mantener la misma performance sin importar la cantidad de usuarios. En terminología de software, tenemos dos opciones:
¿A qué se refieren?
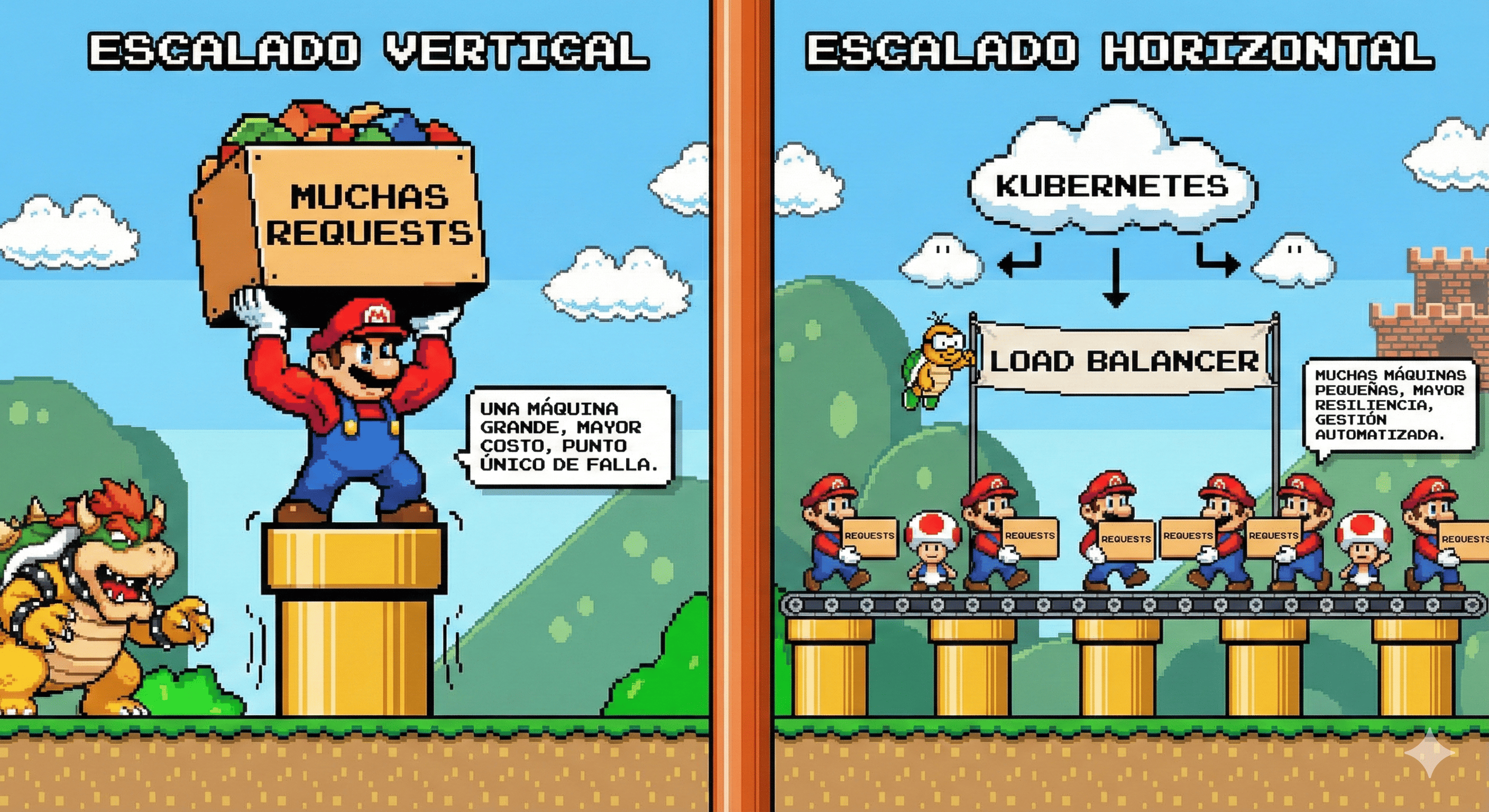
- Vertical: Si queremos soportar el aumento del tráfico, necesitamos tener una mejor máquina. El computador debe tener una CPU más potente, más RAM o mayor capacidad de disco, etc. Esta forma tiene pros y contras: sus pros son principalmente que todo está centralizado, requiere menos tiempo de mantenimiento y tiene un costo inicial bajo. Sus contras son que es sensible a fallos, escalar se vuelve costoso y existe un límite físico.
- Horizontal: Uno para todos y todos para uno. Si no podemos tener una máquina gigante, podemos tener muchas máquinas más pequeñas que hagan lo mismo. Escalar horizontalmente se basa en este concepto: tener computadores más pequeños pero conectados entre sí para soportar la demanda.
¿Cuál elegir?
La elección no es binaria. Como la mayoría de los problemas de tecnología, depende mucho del contexto. Imagínate que eres una empresa con millones de usuarios y creas un nuevo producto; es muy probable que necesites que tu producto escale horizontalmente, ya que cuentas con una gran base de usuarios. Por otro lado, si estás empezando como empresa, no tiene sentido gastar dinero en una infraestructura horizontal, ya que es muy costosa inicialmente y aún no tienes una base de usuarios demasiado grande.
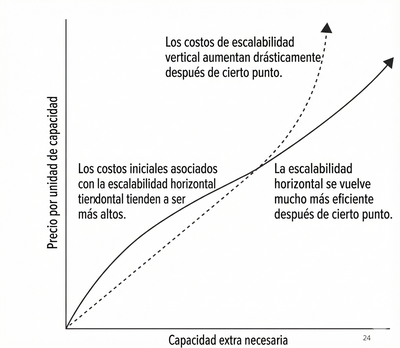
El gráfico muestra que, inicialmente, es muy costoso montar todos nuestros servicios en una infraestructura horizontal, ya que habría servicios que no se utilizarían en su máximo potencial, junto con otros problemas. No obstante, a medida que la demanda aumenta, el costo horizontal comienza a ser menor que el vertical, hasta llegar a una cantidad de requests en la que se vuelve más conveniente mover toda la infraestructura a un enfoque horizontal. El costo horizontal aumenta tanto debido a que si se necesita suportar tantos requests de la aplicación se tendrá que pagar una maquina (VM) muy premium de cloud, que terminará siendo mucho más cara que computadores pequeños.
La magia está en identificar bien este punto y tomar la decisión correcta. En la mayoría de los casos, es una apuesta y, muchas veces, simplemente se toma una decisión según el conocimiento y las estimaciones del equipo (basadas en los datos de costos actual de tu plataforma).
¿Cómo se coordina todo?
Volvamos a nuestro ejemplo. Imaginemos que queremos escalar de forma horizontal, de modo que todos los computadores representan pequeñas hormigas que trabajan en conjunto para cumplir una función. Sabemos que tenemos nuestros computadores, pero ahora necesitamos coordinarlos. Alguien tiene que encargarse de saber si los computadores están sanos, si están conectados, asignar y mover el tráfico, etc.
A este individuo se le llama “Load Balancer”, que es, principalmente, la pieza de software que recibe las peticiones (requests) y decide a qué servidor enviar el tráfico. Sus funciones principales son: evitar que un servidor se sobrecargue, asignar de manera equitativa el tráfico entre los computadores (las “hormigas”), entre otras.
En términos prácticos, es el Project Manager (PM) de los computadores.
¿El problema?
El Load Balancer es una pieza pequeña, pero no lo es todo. Piensa en situaciones donde necesitas crear más servidores porque estamos en navidad y muchas personas fueron al centro comercial, aumentando el uso de la aplicación o cuando necesitas desplegar una nueva versión de tu código. El Load Balancer no hace esto. Solo asigna tráfico según el estado actual de los servidores.
Solución: Kubernetes
Kubernetes es una tecnología creada por Google en 2014 (por Joe Beda, Brendan Burns y Craig McLuckie) que, en términos simples, es un orquestador de contenedores.
Los contenedores son actualmente la forma más confiable y escalable de construir piezas de software porque son agnósticos al sistema operativo. Se ejecutan en una capa superior al sistema operativo y permiten encapsular desarrollos de componentes dentro de un entorno propio, con todas sus dependencias y paquetes.
Entonces…
Kubernetes es la solución para escalar aplicaciones. Esta tecnología, creada por el equipo de Google, permite automatizar la escalabilidad de los productos, entregando toda la infraestructura necesaria dentro de la plataforma y evitando que los equipos tengan que preocuparse en exceso de la configuración, ya que gran parte del trabajo se gestiona internamente en Kubernetes.
En términos prácticos, Kubernetes se representa de la siguiente manera:
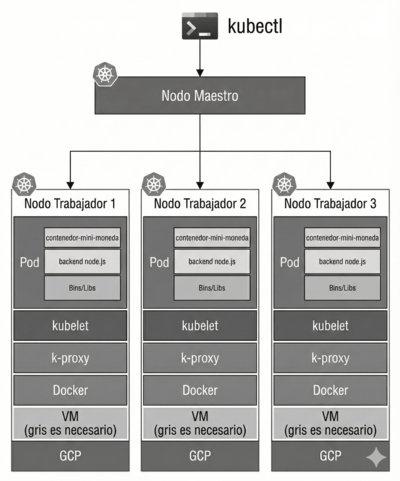
Donde:
- VM: Es la máquina virtual real donde Kubernetes corre. Puede ser de GCP, AWS, Azure, o un servidor propio.
- Docker (o container runtime): Es el sistema encargado de ejecutar contenedores. Kubernetes usa Docker (u otros runtimes) para levantar las imágenes de tu aplicación.
- kubelet:El agente que vive en cada nodo. Funciona como un “cuidador de pods”, y logra: Ejecutar los pods asignados por el maestro, revisa su salud del sistema y reinicia los pods si se caen.
- k-proxy (kube-proxy): Administra la red dentro del nodo. Dirige el tráfico al pod correcto usando reglas de red. Permite que los pods se comuniquen entre sí dentro del clúster.
- Kubenet: Es un plugin de red simple que crea las reglas necesarias para que los pods puedan comunicarse entre nodos.
- Pod: La unidad mínima de Kubernetes. Puede contener uno o varios contenedores que trabajan juntos, comparten red, IP y sistema de archivos temporal.
La magia de Kubernetes es que mantiene la misma infraestructura —máquinas virtuales, contenedores y load balancers—, pero lo administra todo por sí mismo.
Si un nodo se cae, Kubernetes se preocupa.
Si hay que levantar más nodos, Kubernetes se preocupa.
Si tenemos una nueva versión de nuestro producto, Kubernetes se asegura de que todos los nodos actualicen esa versión.
Todo suena muy bien, pero el problema de Kubernetes es que puede ser costoso y, para justificar su uso, es necesario tener un volumen elevado de solicitudes; de lo contrario, no tiene sentido implementarlo.
Kubernetes es una tecnología muy interesante y en pocos pasos se puede configurar en Google Cloude, pero tiene poco sentido usarla si no cuentas con la cantidad de requests necesaria para aprovecharla correctamente.
Conclusión:
Creo que estos temas son interesantes de abordar, ya que no se tocan mucho en los programas de magíster o en los bootcamps de AI/Data Science, pero ayudan a entender mejor la tecnología. Kubernetes es una tecnología más, como muchas otras, pero los conceptos básicos siguen perdurando en el tiempo.
Esta tecnología no existía antes porque no había tantos datos. A medida que ha pasado el tiempo y más usuarios utilizan servicios digitales, un solo computador ya no es capaz de abastecer toda la demanda, y hemos tenido que migrar hacia arquitecturas con más computadores, entre otras soluciones.
Nota: Algunas de las imágenes fueron extraídas desde un curso en la Universidad de Birkbeck (Advance Cloud Computing).